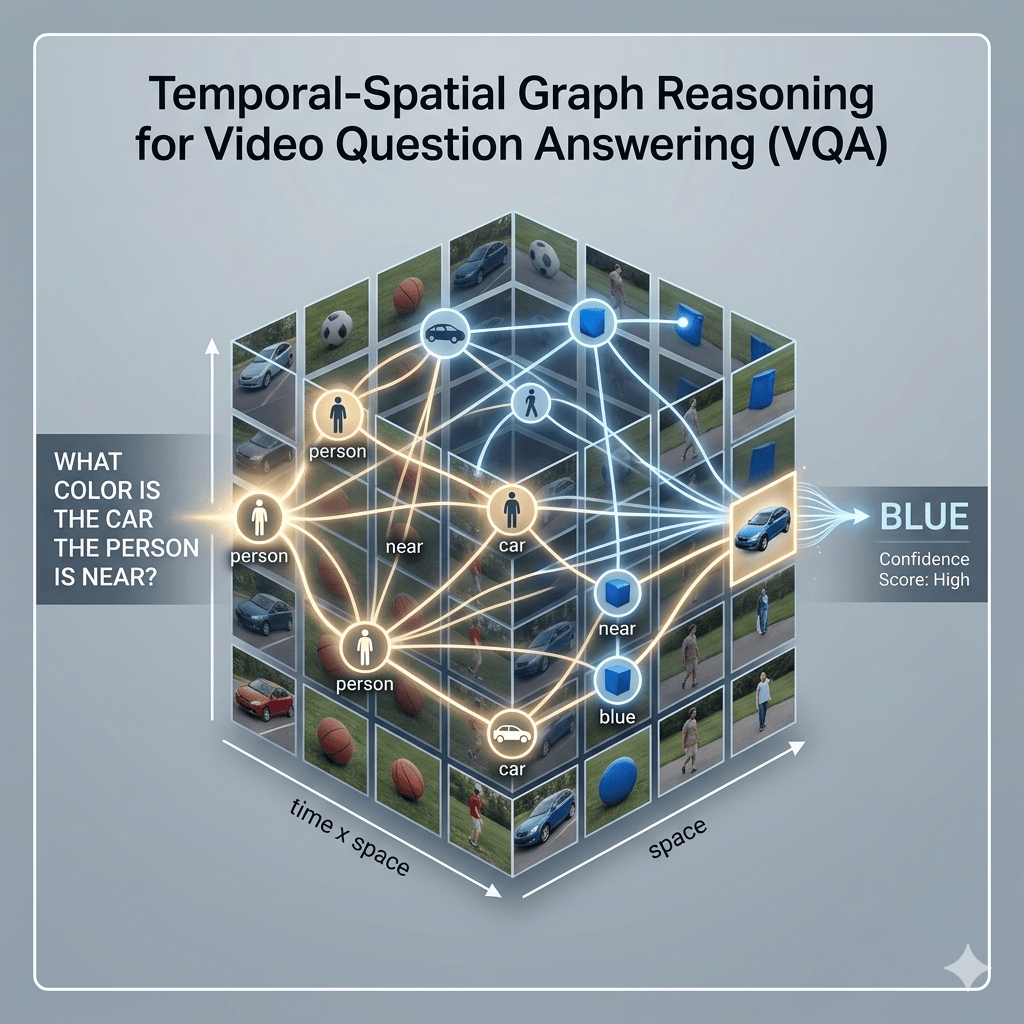
The model integrates transformer architectures with graph neural networks to reason about video content. It identifies relevant visual evidence and highlights spatial regions related to the answer. This approach improves transparency and interpretability in video AI systems.